
Digital Reasoning Sets New Record for the Largest Neural Network Trained

As we all know, neural networks, even though are amazingly helpful in virtually all areas they’re applied, they do have a big drawback: computational power. The larger (and subsequently more accurate) you want your network to be, the more computational power you must allow it to consume. This means that large neural networks must be used on computers that have incredibly huge processing capabilities, something that individuals can’t afford to have.
Fortunately though, some giant tech industries like Google can actually do research on quite large neural networks (take a look at DeepDream), with Digital Reasoning setting a new record for the largest neural network, consisting of 160 billion parameters- that is 148.8 billion more parameters than Google’s previous record of 11.2 billion, and 145 billion more than Lawrence Livermore National Laboratory’s neural network with 15 billion parameters. That’s a lot of billions, isn't it?
Results of this research is published in the Journal of Machine Learning and Arxiv, and will be presented at the 32nd International Conference on Machine Learning in Lille, France, July 6-11. The published paper’s title is “Modeling Order in Neural Word Embeddings at Scale”.
Model Details and Evaluation
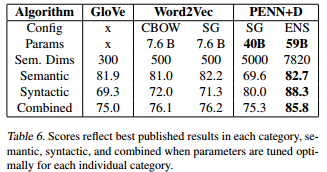
In order to evaluate the accuracy of their model, Andrew Trask, David Gilmore and Matthew Russell used the "word analogy" accuracy criterion. In this technique, the neural network generates a vector of numbers for each word in a vocabulary, and they let the net do math with these vectors. Doing math with these vectors means doing math with the words themselves. Depending on whether the "word math" operations and results have syntactic and semantic relationships, the network’s performance is rated. To better understand how word math is done, take the following example: "king is to queen as man is to woman", which is encoded in the vector space with the equation "king - queen = man - woman". Here's the deal though: this new architecture uses both word-level and character-level representations in the vector space, so as to analyze word structures and shapes as well. And it works.
The vocabulary used is this huge dataset that consists of around 20.000 word analogies and includes both semantic and syntactic queries. The results were pretty impressive: the model had 85.8% accuracy, i.e. it got 85.8% of the word analgies correct. Google's previous score was 76.2% and Stanford's was 75.0%.
Matthew Russell, Digital Reasoning’s Chief Technology Officer and one of the authors in the published paper, stated:
We are extremely proud of the results we have achieved, and the contribution we are making daily to the field of deep learning. This is a tremendous accomplishment for the company and marks an important milestone in putting a defensible stake in the ground towards our position as not just a thought leader in the space, but as an organization that is truly advancing the state of the art in a rigorous peer reviewed way.
Deep learning is getting more and more attention as years go by, and that’s no surprise. It’s the closest tool to what we can have so far in order to create “machines that learn to represent the world”, as Yann LeCun, Artificial Intelligence Research Lab at Facebook, said in an IEEE Spectrum’s interview. It’s what we can use right now to create practical solutions to problems in our ever-changing society.
[Credit: Digital Reasoning]